
朝花夕拾-报文缓存
前言
不同时代的数通网络技术,都有着其当时的贡献。让我们进入时光隧道,跟随前辈的足迹,去探访前辈们垦荒的年代吧。
本文既非产品工程技术文档,亦非原厂文宣,乃朝花夕拾,史海拾贝,温故而知新,文笔粗拙,贻笑大方。
正文
报文缓存一直是数通领域的百花齐放的老话题。它实质上就是如何处理无法立即转发的报文。虽然这是个传统议题,但却一直是数通网络中最具挑战性的问题之一。江山代有新人出,百家争鸣的技术迭代促进了行业的发展。
在实际网络中,影响服务质量的最显著差异是报文丢失、延迟、重新排序、损坏/重复和报文延迟变化。这些特征定义了应用程序的网络质量。报文丢失有很多原因,最明显的是:网络拥塞,软件bug,过滤器(如ACL,uRPF,黑洞),路由不正确,网络收敛等。本文侧重于拥塞造成的损失,因为它与缓存关联度较大。本文同时适用于交换机和路由器。
延迟的主要来源是沿链路的传播延迟、设备标准延迟和链路拥塞缓存(队列延迟)。传播延迟是光速的函数(每公里3.34usec),但评估两点之间链路的延迟必须考虑实际的光纤路径和光纤内部的光折射。传统光纤折射的合理近似值为1.46(取决于光纤品牌和波长),故速度约为5us/km。缓存计算中常见数据是,最大地面传播延迟约为125毫秒,最大非拥塞路由行程时间(RTT)为250毫秒。
设备标准延迟是报文被非拥塞网络设备延迟的时间。这包括将报文复制到不同存储器、执行报文操作的时间和序列化延迟(将报文发送到光纤上的时间,对于更快的链路和较小的报文,这将更少)。在数据中心等低RTT网络中,序列化延迟可能是RTT的重要组成部分(10G为1.2us,1G为12us)。这就是缓存的作用。它的范围从10G链路上的微突发的小延迟一直到1G链路,到当具有大缓存的低速接口遇到持续拥塞时以秒为单位测量的大延迟,特别是在配置不足的无线网络中。
报文延迟变化(PDV)(抖动)是报文延迟的变化,通常是瞬态流量。它采用分散(接收器处的连续报文之间的时间比发射器多)或聚集(报文之间的时间更少)的形式。RFC3393提供了PDV的具体描述。在较高级别,可以通过为报文添加时间戳并比较发送时与接收时两个报文之间的相对偏移量来测量它。然后将该值与其他样本组合以进行分析。”好”或”坏”PDV高度依赖于应用程序上下文。对于语音、游戏应用程序或实时视频,文件传输的可接受PDV可能会产生严重影响。即使对于对PDV不敏感的应用程序,也会对其性能产生影响,因为TCP在确定报文已丢失之前要等待多长时间时会考虑RTT变化。ACK的PDV还可以将有关当前和将来的网络拥塞的重要信息传达给传输协议。
TCP概述
绝大多数互联网、企业和数据中心流量都通过TCP运行。TCP本质上是大多数服务提供商网络设计的”应用程序”,其行为必须与更具体的应用程序(如股票交易,游戏或商业VPN)一起考虑。本节主要讨论TCP,重点介绍它如何与网络报文丢失、延迟和PDV交互,还介绍了TCP的最新发展,它的演进对缓存要求有一定影响。
TCP是一种传输协议,它从应用程序获取数据流(而不是报文),并对其进行可靠的端到端传输。TCP将流划分为多个段,并将它们传递给IP,以便作为报文通过网络进行传输。TCP处理任何丢失段的检测和重新传输,并且在可以按顺序传递之前不会将流的数据传递到应用程序。报文丢失会在段恢复时增加延迟,这在许多网络中可能会很快发生。这意味着在使用TCP时,从应用程序的角度来看,丢失和延迟实际上是等效的。
拥塞控制是TCP用于确定何时传输段的机制。为了实现拥塞控制,TCP首先通过增加传输速率来探测网络,以确定由任何给定时间”正在传输”的报文数表示的最佳速率。一旦找到此级别,它将根据来自网络的信号(传统上是报文丢失和往返时间(RTT))不断进行调整。拥塞控制的较新更新实现了更复杂的算法,在某些情况下,这些算法是由机器学习生成的,远远超出了所能考虑的范围。TCP利用报文包头中播发的接收窗口。接收窗口传达接收端上的可用缓存容量,并在缓存填满时更改。发送端在网络中可能永远不会有比接收窗口值更多的未确认网段,因为这样做可能会导致接收端的缓存溢出。
在最初实现中,TCP会话可以完成3向握手并立即传输接收窗口的整个大小。例如,当接收窗口为8*最大段大小(MSS)时,发送端可以通过10Mbps以太网链路突发8个报文。当时,NSFNet骨干网的速率仅56Kbps,因此8个500字节报文的突发流量将使核心链路阻塞超过500毫秒。由于这种行为以及流量之间缺乏任何仲裁,因而网络非常脆弱,并经历了几次灾难性故障,史称拥塞崩溃事件。
缓慢启动和拥塞避免
TCP拥堵避免方案最初是由VanJacobson和MichaelJ.Karels在1980年代中期观察到拥堵崩溃事件后提出的。由于缺乏拥塞控制,实际上有可能”打破互联网”。这些不仅仅是退化,而且可用带宽下降了三个数量级,即使对于仅相隔几跳的节点也是如此。两位前辈开创性的研究-拥塞避免和控制论文引入了许多管理TCP拥塞的新算法。他们提出了两个关键理论机制:慢启动和拥塞避免,在BSDUnix上通过Tahoe实现,后来被称为”TCPTahoe”。虽然Tahoe不再被广泛使用,但它代表了TCP拥塞控制演变的第一阶段。
从Tahoe开始,TCP会话的每个结束都维护两个独立的窗口,用于确定一次可能传输多少个未确认的段。接收窗口操作保持不变。拥塞窗口动态表示支持流的网络容量。在任何给定时间,两个窗口中较小的一个用于控制可能正在传输的未确认报文的数量。RTT和拥塞窗口大小共同决定了流的总体吞吐量。在确认前一个段时发布新段具有对网络进行计时和步调的效果,并且当此时钟丢失时必须采取措施,该时钟可以通过超时检测到。
TCP拥塞控制的第一阶段称为慢启动。这个名词可能会引起误会,因为它会成倍增加拥塞窗口的大小,但它不允许发送端像以前允许的那样立即填充整个接收窗口。慢启动通过允许每次收到ACK时”正在传输”额外的报文来增加拥塞窗口的大小,每个确认的段都允许发送两个新段。将窗口加倍并尽快发送所有新段会导致突发行为,从而影响缓存要求。拥塞窗口从MSS的某个小倍数开始(最大段大小,默认值为536或在握手期间协商,现在通常为1460字节),并随每个ACK按MSS增长。此算法导致窗口大小呈指数级增长,因此速率可以快速增长。在收到ACK时增加窗口会使窗口大小增加的速率高度依赖于RTT。
下图显示了在慢启动期间使用50毫秒RTT捕获报文传输,并说明了TCP实现在报文组释放时的突发性:
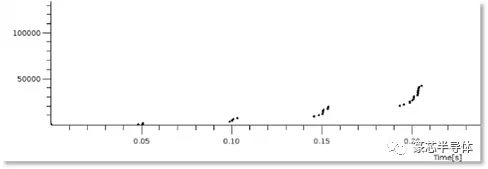
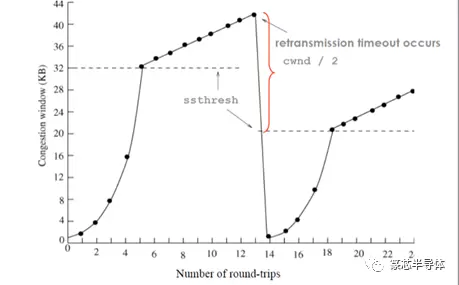
拥塞窗口达到称为慢启动阈值的特定大小后,会话将从慢启动模式转换为避免拥塞模式。慢启动阈值最初设置为较高级别。一旦进入拥塞避免模式,拥塞窗口将线性增加,而不是呈指数级增长-每个RTT只有一个区段。在Tahoe中,如果检测到任何报文丢失,会话将恢复为慢启动,并且慢启动阈值将重置为检测到丢失时拥塞窗口的一半。这意味着会话将在下一个斜坡上以较小的窗口大小进入”避免拥塞”。此机制(将拥塞窗口减半)的结果是,持续拥塞可能导致拥塞窗口大小呈指数级下降,并降低启动速度阈值,从而显著影响会话性能。
TCP拥塞控制的另一个方面是确定在声明由于报文或其ACK被丢弃或损坏而丢失段之前要等待多长时间。此值称为接收超时(RTO)(RFC6298,RFC1122)。将RTO设置得太低可能会导致不必要的重新传输。将其设置得太高将导致对流量损失的检测速度变慢。
由于网络条件的变化(例如,路由路径更改或拥塞),RTO无法设置为最佳情况,甚至无法设置为平均往返时间。而是计算平滑的RTT和RTT方差。RTO设置为平滑的RTT+4倍变化或1秒,以较大者为准。
有关重新传输超时的深入介绍,可参考RFC6298。在Tahoe中,RTO未设置为低于1秒,因此通过RTO检测网络拥塞可能需要相对较长的时间,尤其是在低RTT条件下。TCP的后期发展解决了Tahoe的这一点和其他限制。
下图显示了慢启动、拥塞避免和RTO事件之后的拥塞窗口大小:
作为确认过程的一部分,TCP会在发送方的TCP堆栈无序接收分段时隐式通知发送端的TCP堆栈。当收到同一段的多个ACK时,会发生这种情况。接收端正在通知收到了一个新段,但仍然只能确认前一个段,因为存在间隙。这可以实现快速重新传输。例如,如果接收方具有段0-550并且接收552和553,则551可能已丢失。接收端将为在此方案中接收的每个后续段发送重复的ACK。这是缺口(550)之前最后一段的附加ACK。此信息允许发件人比等待超时更快地重新传输。传统上,快速重新传输会在3个重复的ACK后触发重新传输。这种方法的一个限制会在后续的算法中解决,即它依赖于丢弃段后的额外流量。在小型Web或分布式处理的老鼠流特征中,导致DC(例如Hadoop)的流很少见,流只有几个MSS,因此在丢失的流段之后可能不会发送3个额外的段。此外,此机制不允许TCP识别多个段何时丢失。
最后,在处于非活动状态(大致等于RTO)后,会话应恢复为慢启动状态。这是为了防止会话将整个大型拥塞窗口的流量突发到状态可能已更改的网络中。
TCP Reno- 快速恢复
TCPReno增加了一种快速恢复机制,如果通过重复的ACK检测到丢失,该机制可避免将会话返回到慢启动状态。相反,当触发快速重新传输时,拥塞窗口设置为当前拥塞窗口的一半,并且会话仍处于拥塞避免模式。在解决缺失段时,确认进一步的无序段允许传输新段,同时仍保持允许的传输的段数。重复的ACK不会触发拥塞窗口大小的增加。如果快速重新传输不成功,则会发生超时(RTO),从而导致会话恢复为慢速启动。在Reno中,如果RTT中丢失了多个段,则会发生定期重新传输和重置为慢速启动。如果必须多次重新传输同一段,则RTO时段将呈指数级增长,并且会话性能将受到显著影响。
虽然现在可以使用其他TCP选项,但TCPReno中的机制为现代拥塞控制和重新传输提供了基础。后来的模型主要改进算法和恢复行为,同时仍然遵循接收窗口、拥塞窗口、快速重传和快速恢复模型。
其他拥塞控制算法
后来出现了许多其他拥塞控制机制,如SACK,NewReno,CUBIC,PRR,Vegas,BIC,CompoundTCP,DCTCP,MTCP等。实际上,Linux内核3.14.0支持12种不同的拥塞控制算法,这些算法要么承诺更好的整体性能,要么针对约束延迟等特征进行优化,要么针对专用环境进行优化。拥塞控制算法不是协商的,且对于会话中的每个主机可能不同。这允许操作系统甚至应用程序选择不同的算法,并设置其TCP参数。例如,初始拥塞窗口和初始RTO也可以由客户端设置。虽然在许多网络中,低于1秒的初始RTO是有意义的,但应谨慎行事,因为网络延迟不是RTT中的唯一因素,网关、VPN服务器和延迟的ACK也可能会增加延迟。选择性ACK(SACK)(RFC2018)是一个用于改进累积确认的默认行为的TCP选项。如果没有SACK,当主机收到重复的ACK时,它无法确定除确认分段之后的分段以外的分段是否也丢失,因此它不知道需要重新传输的内容。如果它只是传输第一个未确认的段,则需要完整的RTT来识别另一个缺失的段。有选择地确认区段的能力解决了这个问题。必须在主机之间协商SACK。
NewReno(RFC3782)解决了未启用SACK时多段丢失的情况。在这种情况下,在确认第一次重新传输之前,发件人并不知道多个段会丢失。NewReno在第一次重新传输后检测到其他缺失段时,会更新”部分响应”方案的行为。NewReno是FreeBSD中的默认配置。
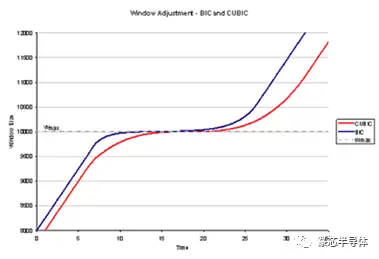
CUBIC改进了TCP在高RTT、高带宽网络上的拥塞控制行为,同时保持了新流和现有流之间以及具有不同RTT的流之间的公平性。其中两项关键创新是利用自最近一次报文丢失以来的时间来扩展拥塞窗口并使用立方函数扩展窗口。立方函数允许窗口在上一个拥塞水平之前迅速增长,但在上次观察到拥塞的水平附近更谨慎。如果之前的拥塞不再发生,则快速扩展将恢复。CUBIC对高带宽高RTT网络有效,因为拥塞窗口的增长不依赖于ACK。CUBIC是Linux和MacOSYosemite中的默认设置。CUBIC是Linux中默认的拥塞控制算法,因此被广泛部署。由于Android使用Linux,所以它也被部署在无线网络中。
下图显示了CUBIC窗口扩展:
TCP比例速率降低(PRR)由谷歌开发,旨在改善快速恢复机制,它与CUBIC等拥塞控制算法结合使用。PRR通过调整重新传输的节奏以及在恢复期间将拥塞窗口减少不到一半来平滑重新传输行为。PPR还引入了一种早期重传机制,当有迹象表明老鼠流可能没有太多额外段时,该机制可减少触发快速重传所需的重复ACK数量。CUBIC+PRR自内核3.2版以来一直是Linux的默认版本。
复合TCP由微软开发,是其几个操作系统中的默认设置。它针对大型环境进行了优化。它通过估计队列延迟并在传统的拥塞窗口大小中添加”延迟窗口”来实现此目的。
Reno的变种版本:BIC,CUBIC和复合TCP都被广泛部署。它们在缓存上分别呈现不同的负载。
拥堵控制的未来研究方向
目前用户主要通过移动网络通过移动设备访问互联网。这些网络使用传统TCP算法,这不是最佳实践。首先,可用的本地带宽可以快速而迅速地变化,在几秒钟内变化几个数量级。其次,与有线网络相比,报文丢失对拥塞的影响较小。
Sprout维护一个不依赖于报文丢弃的拥塞窗口。相反,它根据诸如ACK的到达间隔延迟和RTT变化等因素来预测网络容量。该信息由接收方实时传送回发送方。由于移动应用程序经常在同一应用程序的两个实例之间进行通信,因此它们为自定义传输协议提供了机会。Sprout不是TCP变种,而是备用传输协议。它利用拥塞窗口概念,但与TCP不同,它利用端点之间有关网络状态的通信。在使用真实世界网络带宽跟踪的模拟中,Sprout在快速适应可用带宽的增加和减少以及限制延迟方面的表现显着优于广泛部署的TCP算法。
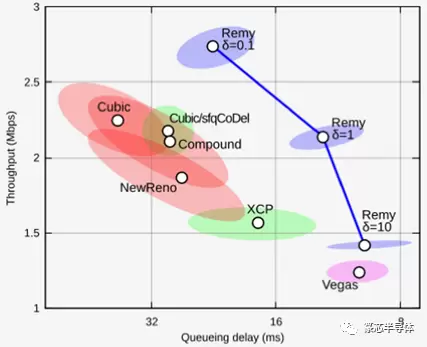
Remy是一个生成拥塞控制算法以适应网络和应用程序约束的程序。它有三个变量,这些变量与未来的可用带宽高度相关。它们是确认的平均到达间隔时间、在这些ACK中回显的发送方时间戳的平均值,以及连接上最新RTT与观察到的最小RTT的比率。然后,计算出的算法将这些值映射到值中,以调整拥塞窗口并调整传出报文的速度。Remy能够为一系列网络条件和应用需求生成拥塞控制算法。单个算法的实际工作原理是未来研究的主题,以对其属性进行逆向工程。使用Remy派生的算法和从无线网络重新创建的跟踪,即使启用了AQM,相对于广泛部署的机制,带宽和延迟也得到了显着改善。与Sprout不同,Remy不需要在端点之间通信拥塞信息,因此可以在TCP中本机使用。Remy算法(针对带宽、延迟或平衡进行了优化)相对于其他算法的模拟结果如下所示。圆圈是带宽和延迟的中位数。周围的省略号显示了发送者之间的可变性(不公平)。这种方法为优化各种环境中特定应用的算法开辟了一条新途径,包括针对数据中心、无线和移动中特定应用的定制。
下图显示了拥塞控制方案吞吐量延迟的中位数和变化(右上角为最佳):
<未完待续>
希望本文能对了解数通网络设备提供一点粗浅的感性认识。
本文有关信息均来自公开资料。