
前言
交换机是数通行业高速发展的一个缩影。“点石成金”的先驱们不懈的探索,使交换机产业迅猛发展。相比于时下的交换机,早期的产品,无论是性能还是功能都有很大差距,但每个产品的出现都有其时代意义。让我们进入时光隧道,跟随前辈的足迹,去探访垦荒的年代吧。
本文既非工程学术文档,亦非原厂文宣,乃见微知著,温故而知新,文笔粗拙,贻笑大方。
<续前文>
3.交换矩阵
接收数据路径执行给定数据帧应转发到哪个输出端口所需的所有必要的限定、分类和表查找功能。传输数据路径根据需要加载限定符,实现优先级和分布策略,并将数据帧发送到相应的输出端口上。交换矩阵位于接收和发送数据路径之间。其功能是在交换机的所有输入和输出端口之间传输数据帧。交换矩阵的设计对于交换机的性能的来说至关重要。目前在交换机产品中广泛使用三种交换矩阵架构:
共享内存
共享总线
Crossbar矩阵
每种架构都被用于将数据帧从输入端口传输到输出端口,各自具有其优缺点。下文将逐一讨论。
3.1 共享内存
共享内存架构是相对最简单的设计,并且在可以使用它的产品中,通常是成本最低的解决方案。因此它是交换机中最受欢迎的交换矩阵设计方法。共享内存交换架构的主要限制是内存带宽,数据移入和移出共享内存的速度将对交换机中的端口数和这些端口上可支持的速率设定上限。
3.1.1 共享内存架构工作流程
共享内存架构使用单个公共内存作为端口之间数据帧的交换机制,如下图所示: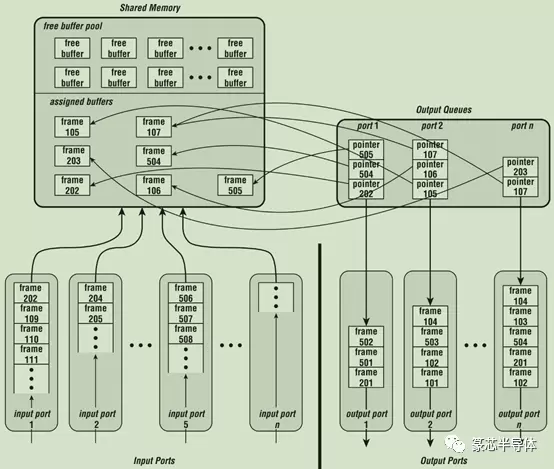
通过输入端口的接收数据路径在到达在共享存储器中的数据帧存储后,被分配并引导到相应输出端口的传输数据路径中。理想情况下,数据帧可以直接从接收端口传输到共享内存中。实际上,接收数据路径中通常需要一定量的端口缓存,在接收和分类期间临时存储数据帧。但大部分系统内存会位于公共缓存池中。
系统启动初期,共享内存中的所有数据帧缓存区为未使用状态。当数据帧从输入端口到达时,系统会将可用缓存区分配给数据帧。根据从查找引擎获得的结果,共享内存中的数据帧将链接到要转发到的输出端口的相应输出队列中。这些输出队列代表要在传输数据路径中处理的数据帧流。
共享内存方法的优点是:为每个端口使用单个大内存而不是单个缓存区内存,这可以降低总内存(和内存控制器)成本。每个端口的输出队列都包含一个缓存区指针的链接列表,这些指针表示存储在共享内存中的数据帧。要将数据帧从输入端口移动到输出端口,只需将指针指向位于目的输出端口的队列中的适当的帧缓存区。查找引擎既可以用单个通用引擎来为所有端口服务的方法来实现,也可用分布式方法来实现,每个端口对其自己的接收数据帧执行查找。在给定数据帧存储在共享内存中之前,可以在该数据帧上完成查找,或者可以在并行执行查找操作时存储数据帧。即在交换机知道如何处理数据帧之前,可以存储数据帧,一旦查找引擎完成其工作,其缓存区指针就可以链接到相应的输出队列。
3.1.2 共享内存架构中的组播
共享内存交换矩阵架构有助于将数据帧从输入端口移动到多个输出端口。由于公共内存可从所有端口访问,因此无需执行多次传输或为组播流量提供特殊数据路径。每个数据帧缓存器都可以提供一个传输端口映射,如下图所示:

查找引擎确定应将数据帧转发到输出端口以进行传输。如果一个数据帧发往多个输出端口(如组播或未知单播),则在传输端口映射中,每个目标输出端口的相应位将设置为1。当输出端口传输数据路径不再需要共享内存中数据帧的副本时(已完成传输或已将数据帧复制到本地端口缓存区),则会清除传输端口映射中其端口的置位,并检查是否仍设置了其他位。一旦传输端口映射中的所有位都清除,则帧缓存区就可以被可用池所回收。
3.1.3 缓存区架构
共享内存按照一系列数据帧缓存区(包括可用缓存池中的任何内存)被组织起来。但没有严格要求给定数据帧必须存储在一个连续的块中。数据帧缓存区可以是连续的,也可以是不连续的。这两种方法都有自己的优缺点,下文将逐一论述。
3.1.3.1 连续缓存区
当缓存区连续时,存储器接口控制器的设计会比较简单。连续缓存区可以通过表示数据帧开始位置的单个指针来标识。用于将数据帧移入和移出共享内存的直接内存访问(DMA)引擎可以用这个单个缓冲区指针进行工作,无需将数据帧进行分段,分散到共享内存的不相交部分。
当数据帧缓存区既连续且又是固定长度时,则会是最为合适的应用场景。使用此方法,可以将整个共享内存预分配到不同编号的数据帧缓存区中。采用此方法时,不需要提供复杂的动态内存分配。但每个固定长度的缓存区必须足够大,才能存储最大长度的数据帧。如果接收的数据帧小于最大可能长度,则内存利用率将会下降。因此,在内存成本和内存接口逻辑的成本之间必须取得平衡。
以太网交换机中使用的一种常见方法是分配2048(2K)字节的固定长度作为连续缓存区。2KB缓存区为最大长度的以太网帧(1522字节,包括VLAN标记等),交换机内部数据帧头、传输端口映射和任何特定于实现的内存控制信息,提供了足够大的存储空间。实际上,可用于此内部开销的526字节(2048-1522=526)远远超过通常所需的大小。但是,如果将整数(二进制)用于缓存区长度,则内存接口控制器可以使用数据帧号作为每个内存缓存区指针的最高有效位,如下图所示:

这就是以降低内存利用率为代价进一步简化了硬件设计。
虽然可以设计使用可变长度连续缓存区的共享内存交换架构,但这通常会增加内存接口的复杂度和内存碎片问题。因此,如果系统无法容忍连续的固定长度缓存区提供的内存效率,通常会选择不连续的缓存区分配方案,因为这既能提供更高的内存利用率,又能提供可变长度的缓存区支持,但又不会引起明显的内存碎片问题。
3.1.3.2 不连续缓存区
不连续缓存区方式,不是将数据帧存储在单个内存块中,而是将单个数据帧存储为分散在整个内存中的一系列数据帧段。因此,数据帧的开始由单个缓存区指针标识,但该指针仅指示数据帧的第一个可能段。通过遍历缓存区指针的链接列表来引用整个数据帧,如下图所示:

链接列表可以存储在输出队列数据结构中,也可以存储在帧数据缓存区段中,其方法是让每个数据缓存区段的末端提供下一个内存指针或指示链接链末端的标志。
每个数据帧段的长度是可变的。通常,硬件会支持最小值,每个段的总长度是此最小值的倍数。不连续可变长度缓存区方法比任何固定长度缓存区方案,会更有效地使用内存。在最差的情况下,分配的未使用的内存量是一个最小长度的缓存区减去1个字节,而不是最大数据帧数。链表缓存区方案可以处理比固定长度方法大得多的数据帧,而不会降低内存效率。
3.1.4 内存带宽限制
如果系统可以使用共享内存交换架构,那么就应该尽量使用共享内存架构。共享内存架构通常是交换机设计可用的最简单、成本最低的解决方案。但并非所有的交换机设计都选用共享内存交换架构方法。由于所有数据帧都必须通过单个通用共享内存,因此内存接口的速度最终将限制交换机的容量。例如,一个具有32位宽的数据路径的内存系统,使用10ns同步静态RAM(SSRAM)和100MHz时钟。每个数据帧必须至少通过内存接口两次:一次是从输入端口写入时,一次是读入输出端口时。这会将可用内存带宽减半。即使在流数据的最佳情况下(即,10ns内存访问时间只能用于多个顺序读取或写入数据,而不是单个随机访问),交换机容量也限制为:32位×100MHz÷2=1.6千兆字节/s。但是在实际情况下,是无法通过同步RAM获得数据流的全部好处。由于流式处理会带来实际性能的提升,所以这会是用于将数据帧移入和移出内存的消息传递系统设计的必要功能。通常,可用内存带宽将达到最大值的50%至70%。此外,为了防止无限制的排队延迟,有效内存带宽应至少不足30%。这导致可用的非阻塞交换机容量约为原始内存带宽的35%到50%,或者在刚才给出的示例中约为550至800Mb/s。
假设所有端口都采用全双工操作,此容量足以满足端口数为24至48或更高的10Mb/s交换机,对于具有两个百兆上行链路的48端口10Mb/s交换机来说,此容量也足够了。但这无法为八个以上的百兆端口提供非阻塞操作。因此,给出的设计示例仅适用于桌面或小型工作组交换机应用程序。
3.1.5 增加内存带宽
有多种方法可以用来增加内存带宽,以便共享内存交换架构可用于更高性能的交换机:
使用最快的存储器:更快的存储器将允许系统使用更高的时钟速度,而不会产生等待状态。但是,半导体RAM的速度始终存在各种限制。最快的内存总是最贵的,这实际上也抵消了使用共享内存架构的好处。
使用更宽的内存数据路径:虽然内存本身可能受时钟速率限制,但可以通过拓宽数据路径来增加总内存带宽。由于可以在单个时钟周期内传输更多位,因此内存带宽将与内存接口的宽度成比例地增加。在上述示例中,调整为64位宽的数据路径将使内存带宽加倍。这将使交换矩阵支持具有12到16个端口的非阻塞百兆工作组交换机。标准存储器通常用于16位、32位或64位宽的数据路径。内存技术的进步会大大提高内存密度。
使用非传统内存:与其简单地拓宽传统内存阵列的数据路径,不如采用其他内存设计的技术路线来提高接口带宽,如:
图形RAM(GRAM):与交换机一样,显卡通常需要比传统计算机内存更宽更快的内存。但由于容量较低且市场有限,因此它们比传统RAM更贵。
Rambus动态RAM(RDRAM):RDRAM专为高性能PC、工作站和服务器而设计,支持600MHz或更高的内存接口时钟速度。同样,这种更高性能的内存价格更高,尽管RDRAM能够将共享内存交换机结构的使用扩展到更高端的交换机。
使用嵌入式存储器:即使想采用32MB、256位宽的SSRAM以实现4到6Gb/s的交换机容量,将内存阵列连接到交换机逻辑的其余部分所需的大量引脚也会成为问题。高性能交换机使用的ASIC的大部分成本与IC封装要求有关。如果仅连接到存储器就需要超过256个引脚(除了存储器数据路径线之外,还需要很多仲裁、控制和电源信号等),这将大大增加成本。
一种替代方案是将存储器嵌入到交换机ASIC本身中。如果存储器是内部的而不是外部的,则不需要引脚(或其关联的焊盘)。此外,内部逻辑的时钟速度比外部存储器快得多,因为引线电感更低,驱动电流也更低。512位或更多的嵌入式存储器数据路径可以以很少或没有成本损失来实现。
如8ns、1024位宽的嵌入式SRAM的原始内存带宽为128Gb/s。即使无法以最高的效率使用这种带宽,但这种设计也可以轻松支持具有16至24个千兆以太网端口的无阻塞园区级交换机。
此外,内存大小可以根据交换机的要求而进行定制。没有必要被厂家内存芯片的规格所限制。当然,嵌入式内存也有其自身的一系列问题:
大容量嵌入式存储器会占用ASIC的大部分可用芯片空间。DRAM占用的空间较少,但通常只能以较慢的时钟速度运行。成本上看,嵌入式内存比商用内存芯片贵。并非所有半导体制造工艺都支持嵌入式存储器,这会限制可用的供应商的数量。尽管存在一些问题,但随着半导体密度的增加和嵌入式存储器逐渐成为一种成熟的产品,这种方法对于新的交换机设计将越来越有吸引力,并将共享存储器架构的使用扩展到更高的性能水平。
将嵌入式内存用于交换机架构本身是不切实际的(通常需要大量内存),嵌入式内存也可用于输出端口队列数据结构或查找和/或分类引擎所需的内部存储。
3.2 共享总线
在过去,由于内存比较慢,所以大多数嵌入式处理器系统都是围绕16位宽的内部数据路径设计的。在该环境中,共享内存交换架构的可用交换容量是非常有限的。因此,共享存储器仅适用于端口密度低的交换系统。如果交换机包含更多端口,或以较高数据速率运行的端口,则通常需要更改架构设计。
共享总线体系架构使用公共总线作为端口之间数据帧的交换机制,而不是公共内存。如下图所示:

每个端口(或一小组端口)都有自己的内存,用于输入和输出队列,具体取决于设计。这种方法的主要优点是:共享总线通常可以提供比传统共享内存更高的带宽。例如,32位、33MHzPCI的理论最大容量略高于1Gb/s。专有总线可用于通过使用更宽的总线宽度或更快的时钟来实现更高的容量。1Gb/s共享总线体系架构可以支持中等数量的百兆端口(通常为8个)或大量10Mb/s端口。
共享总线在每次处理中仅访问一次(而不是像共享内存那样一次输入,一次输出),因此相对于共享内存方法,有效容量增加了一倍。共享总线架构为组播传输提供了一种自然机制。它将数据帧传输到单个输出端口或多个输出端口需要相同的时间和总线容量。
共享总线体系架构可以支持分布式查找引擎(即每个接口上有一个引擎)或共享的通用引擎,具体取决于系统的性能要求。共享引擎可以连接到用于数据传输的同一总线,也可以连接到单独的专用控制总线。在前一种情况下,一些总线容量用于将数据帧头信息传输到查找引擎(并将查找结果返回到请求接口),此容量也不能用于数据传输。后一种情况带来了提供两种总线架构的更大成本和复杂性。
共享总线体系结构的缺点包括:
每个端口(或端口组)都需要单独的内存:由于端口之间没有通用的共享内存,因此每个接口模块必须为输入和输出排队的数据帧存储提供本地内存。每个接口上的内存大小必须针对通过端口的预期最坏情况负载进行调整。根据流量模式,某些端口可能会变得内存不足,而其他端口接口上提供了充足的可用缓冲区。当所有数据帧共享一个公共缓存池时,内存可以更有效地使用。即负载分布的统计性质允许共享内存支持给定内存容量的更多流量。因此,对于给定的性能级别,共享总线体系架构将比共享内存系统需要更多的内存,但这会增加成本。
仲裁共享总线:共享总线看起来非常类似于内部高速LAN。因此每个端口必须争夺总线的使用权。授予访问权限后,端口将使用总线将数据帧从其本地内存(输入队列)传输到目的端口的本地内存(输出队列)。
多个输入队列:根据最严格情况下的总线延迟,可能需要优先级仲裁机制和/或不同优先级的多个输入队列。这种效应在crossbar矩阵架构中更为普遍。
许多早期的模块化网络设备的产品文献突出地展示和吹捧了它们的背板容量。这通常是系统使用共享总线架构的明确信号,共享背板总线的容量引导潜在用户了解可以在系统中配置的接口的数量和速率,同时保证了非阻塞操作。
共享总线架构的扩展性不好。如果不重新设计所有交换机端口接口(特别是用于连接和仲裁共享总线的ASIC器件的情况下),通常不可能提高数据速率或总线宽度。大多数现代交换机使用共享内存或crossbar矩阵结构,而对共享总线的需求很少了。随着内存变得更便宜、更快、更复杂和/或嵌入,共享总线可能带来的小改进通常不足以提供更多的收益。
<未完待续>
希望本文能对了解数通网络设备提供一点粗浅的感性认识。
本文有关信息均来自公开资料。